Transformers and State Space Models: A Connection in Sequential Data Modeling
Over the past several years, decoder-only Transformers have become the dominant paradigm for sequence modeling, particularly in large-scale language modeling. At the same time, state space models, including architectures such as Mamba, have emerged as compelling alternatives, offering linear-time scaling and strong long-range modeling capabilities.
The paper (Mamba 2) presents a striking unification of these two paradigms. It shows that decoder-only Transformers and state space models are not fundamentally different mechanisms, but rather two computational views of the same underlying structured operator.
This perspective, called Structured State Space Duality, provides both conceptual clarity and practical algorithmic benefits.
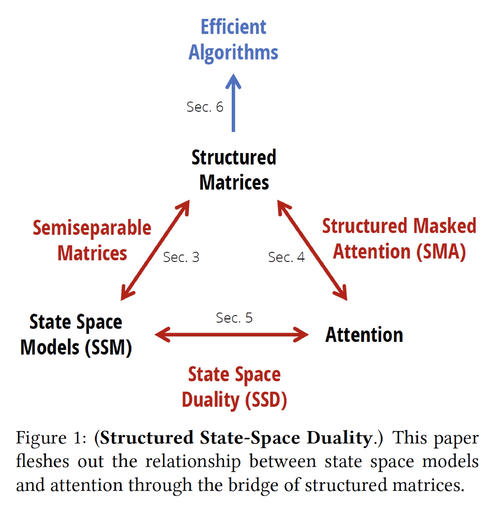
The Key Insight: Structured State Space Duality
This duality connects three central objects in sequence modeling:
- State space models, defined through linear recurrences
- Attention mechanisms, defined through pairwise interactions
- Structured matrices, algebraic objects that admit fast multiplication
The central claim is elegant:
Both state space models (linear recurrent form) and masked attention (quadratic parallel form) can be expressed as multiplication by a structured matrix.
In other words, recurrence and attention differ not in what they compute, but in how the same structured operator is evaluated.
Two Complementary Views of Structured Matrices
The paper develops this unification by presenting two equivalent views.
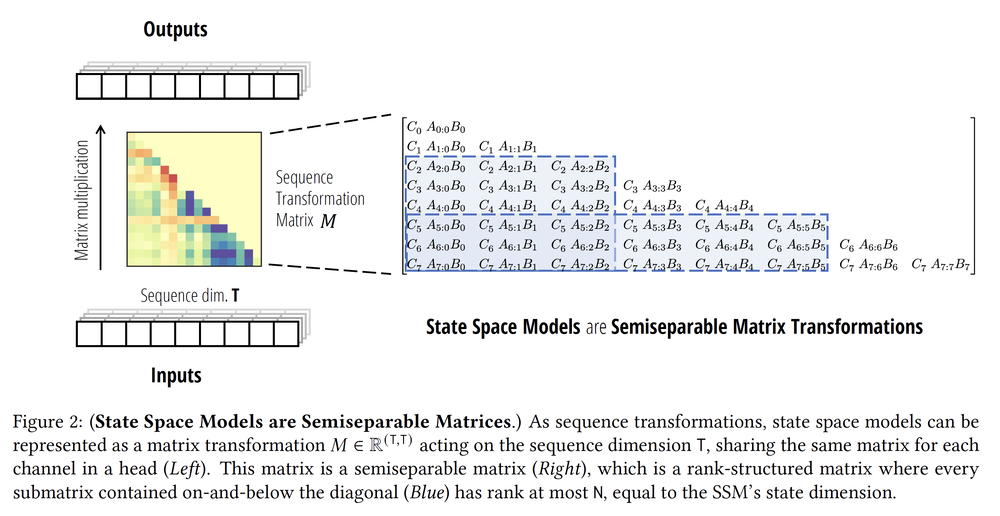
View 1: State Space Models as Structured Matrix Multiplication
A state space model is typically defined by a recurrence: $$ \begin{align*} \state_{t+1} &= A_t \state_t + B_t \input_t \\ \output_t &= C_t \state_t \end{align*} $$
Here, $\state_t$ denotes the hidden state, $\input_t$ the input at time $t$, and $\output_t$ the corresponding output. This formulation appears inherently sequential: each step depends on the previous one.
However, the entire input–output mapping over a sequence of length $T$ can be written compactly as: $$ \Output = \StructuredMatrix \Input, $$ where $\Input \defined \input_{1:T}$ and $\Output \defined \output_{1:T}$ are the input and output sequences, and $\StructuredMatrix$ is a structured matrix (lower triangular) that encodes the cumulative dynamics induced by the time-varying matrices $A_t$, $B_t$, and $C_t$. What appears to be a recurrence is, in fact, a structured matrix multiplication in disguise.
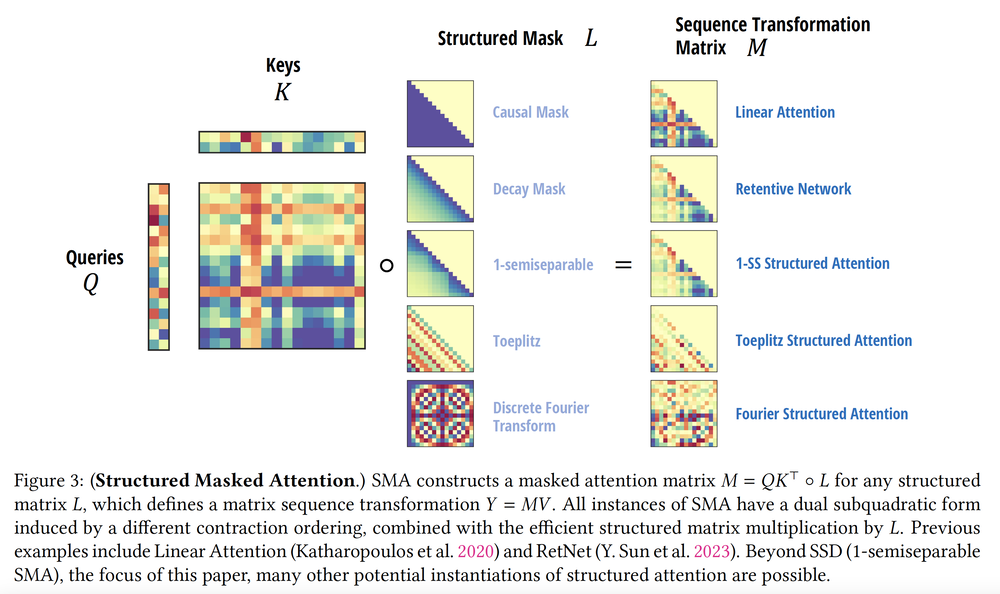
View 2: Masked Attention as Structured Matrix
Masked self-attention is typically written as: $$ \Output = \big((\Query \Key^\transpose)\elementwiseMultiply \Mask\big)\Input. $$
Here, $\Query$, $\Key$, and $\Input$ denote the query, key, and value sequences, while $\Mask$ is a structured mask (e.g., causal mask). The result can be rewritten as: $$ \Output = \StructuredMatrix \Input, $$ where $\StructuredMatrix$ now encodes both attention weights and the structured mask.
Unlike state space models, this formulation is fully parallel and scale quadratically in sequence length. Yet algebraically, it is still multiplication by a structured matrix—one that shares deep similarities with the state space model's view point.
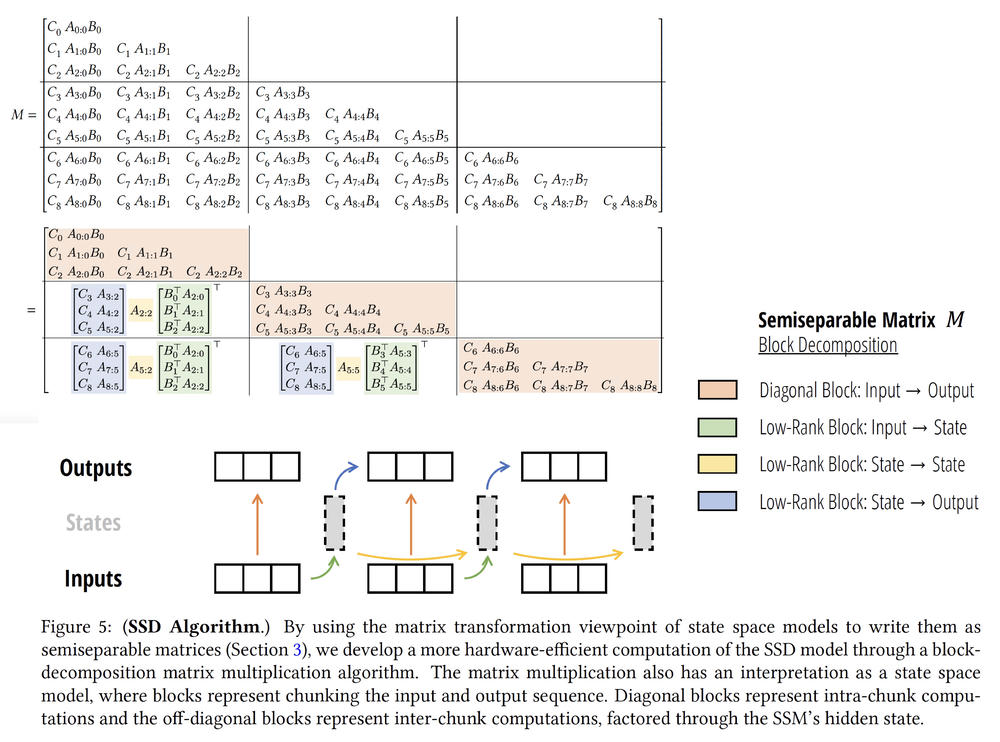
From the Dual-View to Efficient Algorithms
The unifying viewpoint is that both constructions yield structured matrices belonging to the same family (semiseparable matrices). These matrices admit:
- A recurrent state-space evolution (linear-time in sequence length), and
- A parallel attention mechanism (quadratic but hardware-friendly).
Thus, state-space model and masked attention are simply two different contraction orders of the same structured operator. This duality explains why:
- State space models scale linearly in $T$ but appear sequential.
- Attention scales quadratically but is highly parallelizable.
- Both can be derived from a shared algebraic foundation.
Efficient Algorithms via Structure
Exploiting this structured representation, the authors derive efficient algorithms by decomposing $\StructuredMatrix$ into low-rank block components.
This structured approach yields the following computational trade-offs:
| $\quad$ Attention $\quad$ | $\quad$ State Space Models $\quad$ | $\quad$ Structured Matrices $\quad$ | |
|---|---|---|---|
| Training FLOPS | $\Order(T^2N)$ | $\Order(TN^2)$ | $\Order(TN^2)$ |
| Inference FLOPS | $\Order(TN)$ | $\Order(N^2)$ | $\Order(N^2)$ |
| (Naive) memory | $\Order(T^2)$ | $\Order(TN^2)$ | $\Order(TN)$ |
| Matrix Multiplication | $\checkmark$ | $\checkmark$ |
$^*$ The notation $N$ here is the hidden state dimension, and $T$ is the sequence length.
The key takeaway is not merely improved constants, but a conceptual reframing: once we recognize the shared structured matrix, we can design algorithms that interpolate between recurrence and attention depending on hardware and scaling constraints.
Broader Implications
Structured State Space Duality reframes the design space of sequence models. Instead of asking: Should we use recurrence or attention? We can ask: Which structured matrix representation best satisfies our computational and modeling constraints?
As sequence lengths grow and hardware efficiency becomes increasingly critical, this algebraic unification may shape the next generation of large-scale models. Transformers and state space models are not competing paradigms; they are complementary views of the same structured computation.
This post is based on Transformers are SSMs: Generalized Models and Efficient Algorithms through Structured State Space Duality by Prof. Tri Dao and Prof. Albert Gu, adapted here for a broader audience interested in the theoretical foundations of modern sequence modeling.