Belief Net: Bridging Probabilistic Modeling and Deep Learning for Sequential Data
This research, co-authored with Prof. Prashant G. Mehta and my mentee Reginald Zhiyan Chen at the University of Illinois Urbana-Champaign, addresses a long-standing challenge in sequential data modeling: how do we combine the rock-solid interpretability of Hidden Markov Models (HMMs) with the powerful optimization of modern deep learning?
The Problem: Interpretability vs. Optimization
For decades, researchers have faced a "pick your poison" scenario when modeling sequences:
-
The Baum-Welch Method (an Expectation-Maximization algorithm): The classic approach for learning HMMs. It’s interpretable, but slow, computationally intensive, and notorious for getting stuck in local optima.
-
Spectral Algorithms: Extremely fast and provably correct, but they often produce "probabilities" that aren't actually valid (e.g., negative values) and fail when the hidden state space is larger than the observation space (the "overcomplete" setting).
-
Transformers: The current gold standard for prediction. They are incredibly powerful but remain "black boxes"—you can’t easily look under the hood to see the underlying transition or emission logic.
We asked ourselves: Can we train an HMM like a Transformer?
Our Solution: Belief Net
The Belief Net is a framework that formulates the HMM's recursive "forward filter" as a structured neural network. Instead of abstract weights, the learnable parameters in Belief Net are explicitly the logits of the initial distribution, transition matrix, and emission matrix. This means that every parameter has a clear probabilistic interpretation, and the entire model is fully differentiable and trainable end-to-end using standard deep learning techniques.
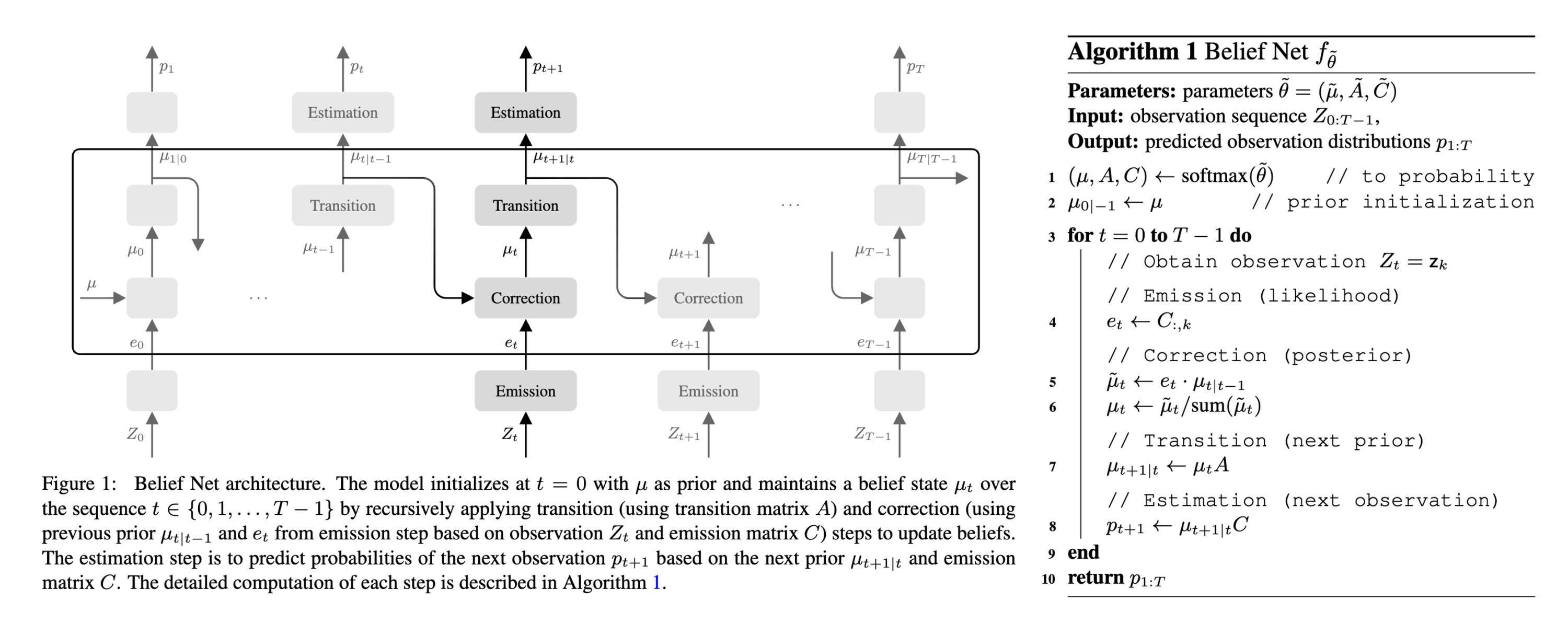
Performance Highlights
We put Belief Net to the test against classical baselines (Baum-Welch and Spectral algorithms) and modern Transformer architectures (nanoGPT) on two tasks:
Task 1. Synthetic HMM Data
Belief Net consistently outperformed the Baum-Welch algorithm in both convergence speed and accuracy. Notably, it succeeded in overcomplete settings where spectral methods completely failed due to rank deficiencies.
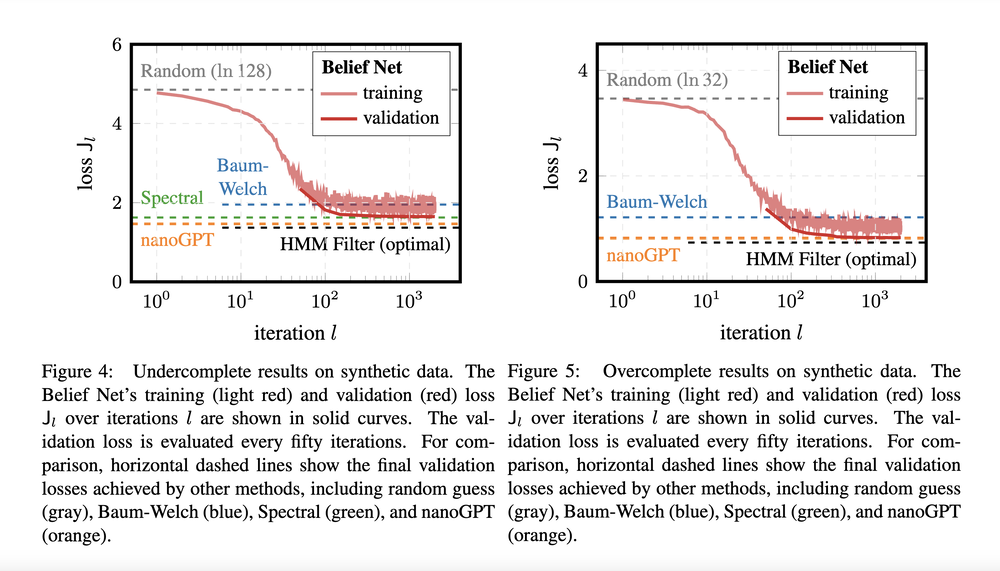
Task 2. Real-World Text Data
When tested on the Federalist Papers dataset, Belief Net achieved lower perplexity than classical HMM methods. While Transformers (unsurprisingly) still lead in raw predictive power, Belief Net provides something they can't: Interpretable Logic.
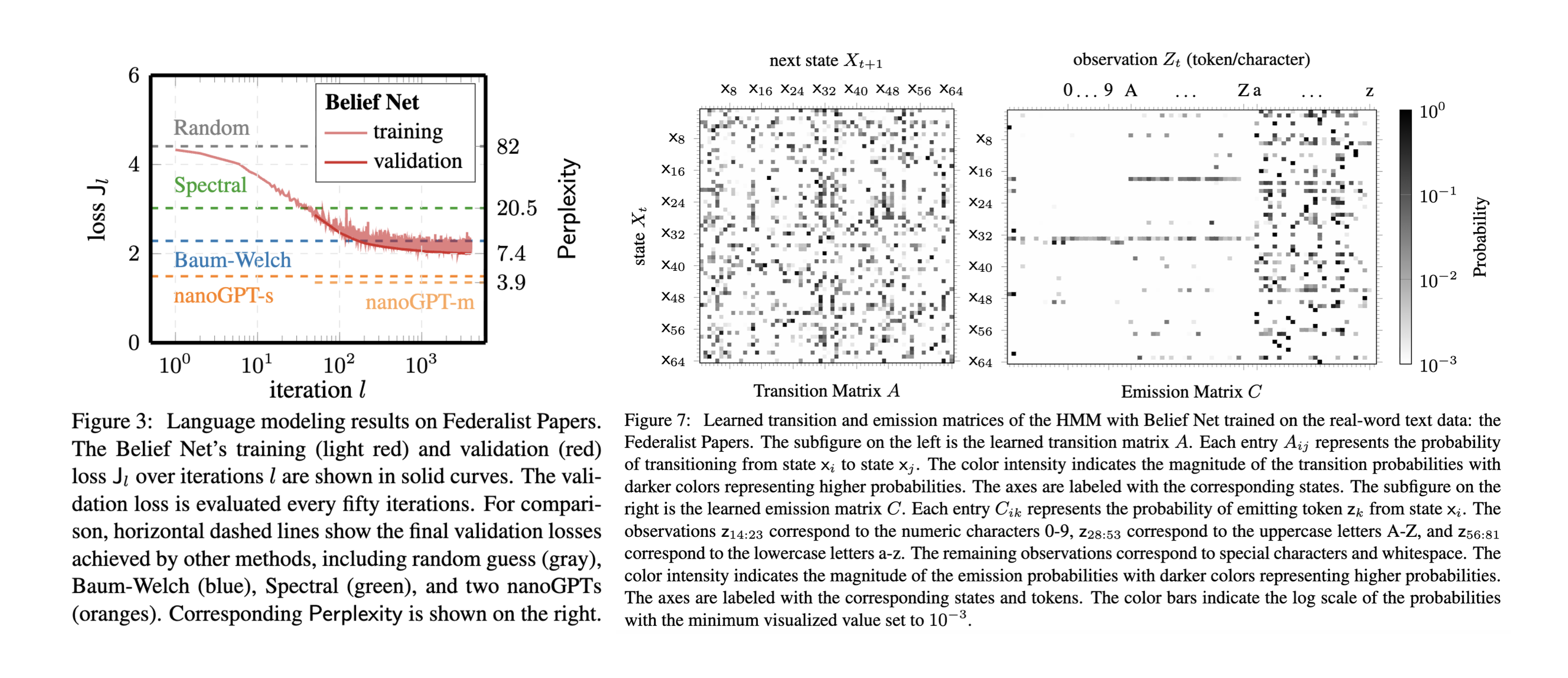
As shown above, we can actually see what the model learned—identifying specific states responsible for emitting uppercase letters or digits, providing a level of transparency that "black-box" models lack.
Looking Ahead
Belief Net is more than just a faster HMM; it’s a bridge between system identification and representation learning. We are excited about future extensions into Partially Observable Markov Decision Processes (POMDPs) and integrating these interpretable filters into reinforcement learning and control pipelines.
This work, Belief Net: A Filter-Based Framework for Learning Hidden Markov Models from Observations, has been accepted to the Learning for Dynamics and Control conference (L4DC 2026).